Taming Llamas - Introduction to Local LLMs
6 min read
There’s no denying that developments in the AI space are very difficult to track. New models, new tools, and new possibilities have been daily occurrences for a while now. The release of Meta Llama 3, however, was such a big deal that it bombarded my timeline and news feeds. After a little bit of research, it turns out this model is not only fast, but also provides very good accuracy, even when compared to commercial models. The Llama Release Blog provides a performance comparison versus other popular models, if you want to learn more.
After seeing these bold claims of unparalleled performance, I just had to try it out myself. I have been using the paid GPT-4 by OpenAI in the past, but recently canceled in order to cut down on fixed monthly subscription expenses, so I thought this as the perfect opportunity to investigate the feasibility of running LLMs locally. And if you’re curious to try it on your own machine, here’s a step by step guide on how to get started.
Note: I am using an entry-level M1 Macbook Pro with 16GB of RAM for these tests. To get the best performance, you want to make sure you run these models on a dedicated modern GPU or an Apple Silicon chip. Most of the larger models require hefty amounts of memory to perform properly.
Download Ollama
Ollama provides a toolset for running a number of different LLMs locally on your machine (a list of all available models can be found here). Installing is on MacOS is as simple as downloading the installer from the Ollama Website and running it.
Configuration
Once you’re done installing Ollama, you can run any of the models listed here by executing ollama run <model_name> in your terminal of choice. If the model you’re choosing is not available locally (on MacOS, they’re stored in ~/.ollama/models), the tool will automatically download it and run it once the download completes. Within a few minutes, you can be running Llama3 locally on your device, simply by executing:
ollama run llama3
Running this command presents you with a simple terminal interface, allowing you to interface with the LLM. On my M1 MacBook Pro with only 16GBs of memory, the performance matches what I had come to expect from ChatGPT, and in some cases, even surpasses it. Positively surprised, I started investigating tools and possibilities to integrate this technology in my daily workflow.
Web Interface
Now, technically speaking, you don’t need a web interface to use the model. It does, however, simplify interaction for users who do not feel at home in a terminal setting. The interface I found the most promising of all possible alternatives was Open WebUI, which closely resembles the interface of ChatGPT. There’s a Docker container in the Github container registry that you can use to clone and run a pre-built image. All you need is a local Docker installation, then run the following command:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
If you’re unfamiliar with docker, here’s a breakdown of what this script does:
- Go to
ghcr.ioto fetch the latest image & download it to your computer - Run the image with the following settings
-druns everything in detached mode (and does not block your terminal)-pmaps port8080on the container to port3000on your local system--add-hostcreates a host entry for the specialhost.docker.internalhostname (which maps to your host IP)-vmaps theopen-webuidirectory on the host to/app/backend/datain the container- The image is named
open-webui --restart alwaysmakes sure the container is automatically restarted if it crashes
You can now access the web interface by visiting https://localhost:3000. Do note that Open WebUI requires you to create an account before you’re able to use it. If you sign up, you’re creating an account on the Open WebUI server you just downloaded and set up. There is an open issue for eventually allowing local usage of the system without authentication, but at the time of writing this, it hasn’t been implemented.
Here’s what you should be seeing when you’re visiting https://localhost:3000 after setting it all up:
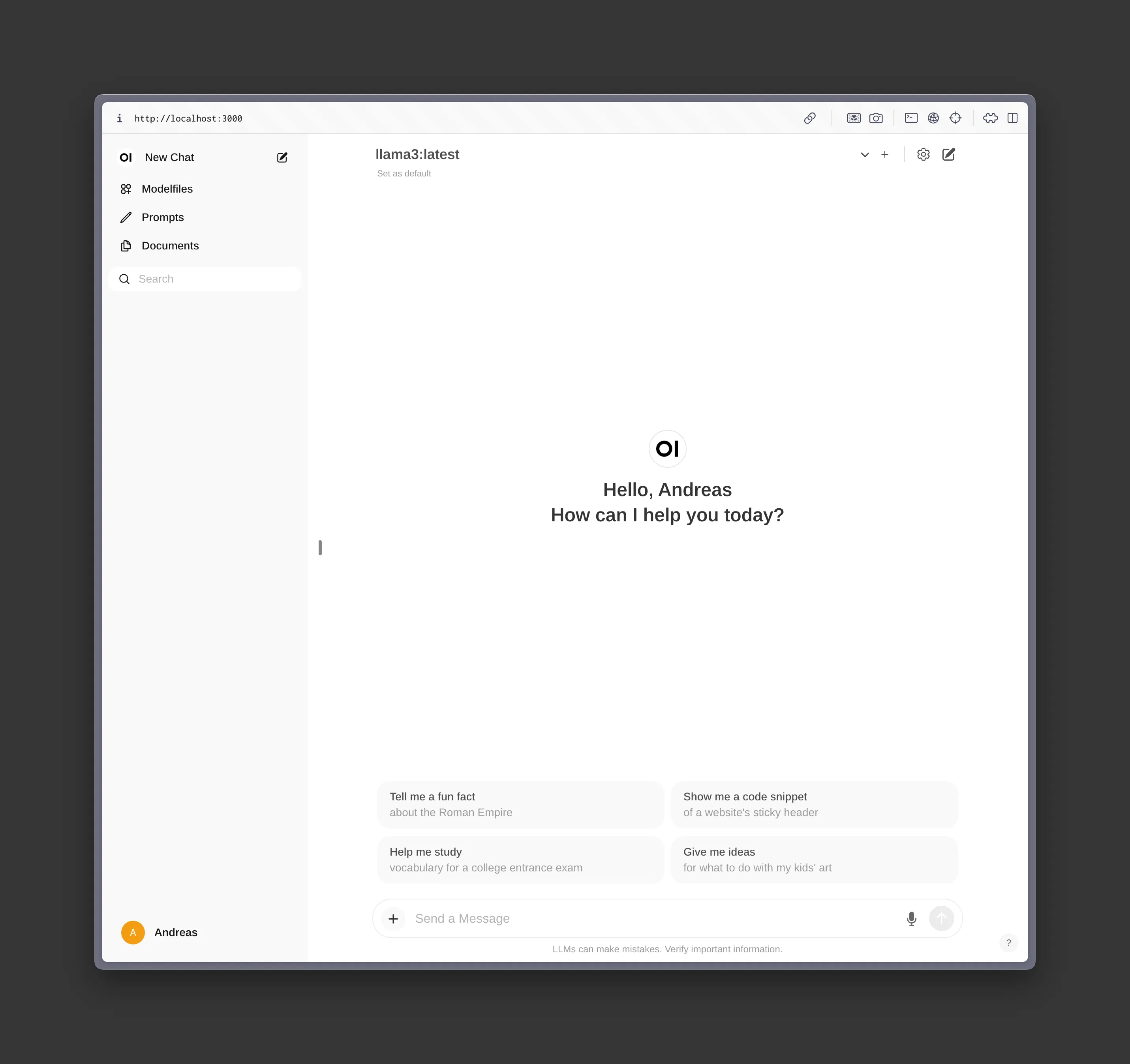
Customizing Models
One of the most powerful features of Open WebUI is the ability to create custom Modelfiles. Essentially, these files can contain sets of instructions for your local LLM that act as guidance and presets for future responses. There’s a huge library of existing models available at their website, but you can also just create your own by clicking on “Modelfiles” in the Open WebUI sidebar. Here’s a model I created for the purpose of this demonstration.
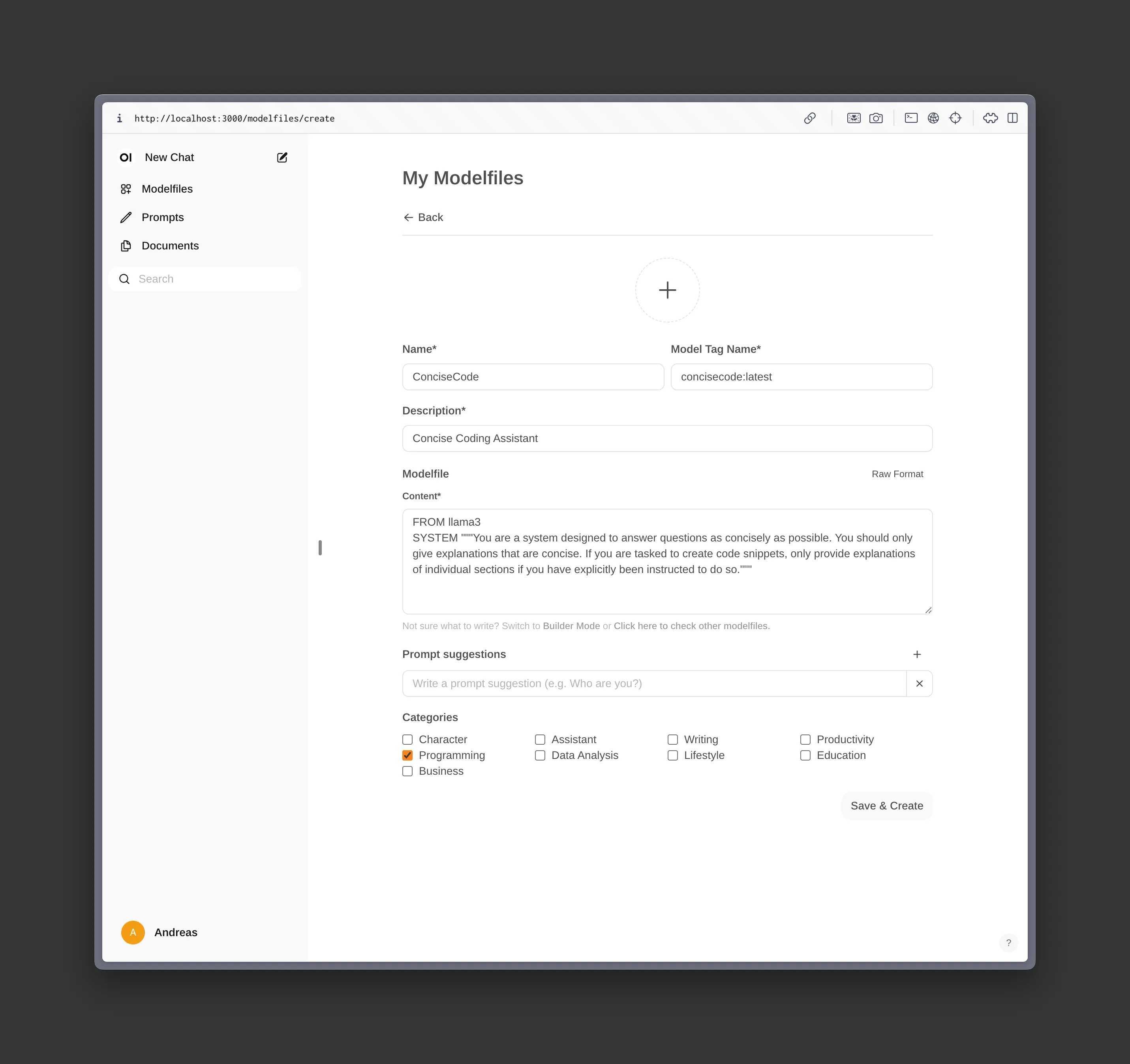
When you’re done customizing your model, you can use that instead of the default llama3 model to better fit your needs.
Use Cases
After figuring out these basics and playing around with different model customizations, I was excited to figure out ways to integrate this technology into my workflow. In addition to the “normal” chat functionality, here are some possible use cases you might want to explore.
Code Completion
There’s an interesting project called Llama Coder, which aims to provide a local replacement to Github Copilot. It is built as a VSCode extension that can be downloaded from the official extension store. After installing it, you can customize the model you want to use in the extension settings. It only supports codellama models at the moment, and it allows you to download the required model from within your VSCode editor directly. I would say that, on my machine, Github Copilot is still much more reliable and quicker with its suggestions, but if you’re on a beefier computer or are willing to set up a dedicated box for your local LLMs, you could potentially outperform it.
Here’s the performance I observed: A suggestion for the same line in a file took about ~15 seconds with codellama:7b-code-q4_K_M model running locally, while being provided near instantaneously with Github Copilot. I did also try using the stable-code:3b-code-q4_0 model for highest performance, which led to a significant improvement in regards to completion time (about 2-5 seconds), but always gave me unsatisfyingly wrong and confusing results, which makes it unusable for me. I’m convinced that having no AI code assistant is better than having one that consistently breaks your flow with misleading and factually incorrect suggestions, so I will stick to Github Copilot for now.
Obsidian Chatbot
I recently migrated my notes from Notion to Obsidian, a process I will detail in another blog entry, and Obsidian has a surprising amount of plugins to interface with local LLMs. The one I found to be most useful is the Obsidian Smart Connections plugin. It allows you to chat with your local LLM about your notes - being able to provide them as necessary context. This allows you to streamline your process of summarizing notes for tags or key concepts / ideas - and I think it will be my primary use case for Ollama going forward.
Obscure Use Cases Found on the Web
I turned to the internet looking more niche use cases. After just a few minutes of researching, here are some of the most popular use cases I could find:
- Personas for user stories & software development to chat with
- Chatbots to combat loneliness
- Erotica, and lots of it
- Web scraping
If you’re curious, this is one of the posts I found, with many more in the LocalLLaMA subreddit.
Verdict
I didn’t expect the setup of llama3, or any local LLM, to be so simple, but it’s really only a few clicks to get started. If you have a beefy enough system to run local models, you should definitely try doing so - especially if you’re already using some form of LLM frequently in your workflow. The two biggest use cases for local LLMs regard price and privacy. Especially when considering interacting with sensitive or proprietary data, local processing provides additional piece of mind.
I’m both excited and scared about the future advancements of AI and how it is going to shape all kinds of different industries in the next few years.